
Top 50 file formats in the KB e-Depot
The current version of the KB’s digital repository system (e-Depot) doesn’t include any tools for automated file format identification yet. Our previous DIAS system didn’t have identification functionality either. As a result, information on file formats in digital our collections is largely based on publisher metadata and file extensions. Neither are necessarily correct. Moreover, previous analyses revealed a number of prevalent file extensions that could not be easily linked to a specific format. One result of this situation was that we couldn’t even reliably tell to what extent patrons were able to view e-Depot content on the PCs in our reading rooms (the obviously common formats aside).
To get a better view of the formats in our collection, we did an analysis of the “top 50” most prevalent file extensions in our e-Depot: what are the corresponding formats, can these formats be automatically identified, and can we render them in our reading rooms? This blog post summarises the main findings of this work.
Extension counts
As a first step, we compiled a list with file counts for every unique file extension in our e-Depot. Importantly, we did this for all files on the file system, including main files, supplemental content and (original) metadata files. The following chart shows the number of files for every extension, sorted in descending order (note that the vertical axis has a logarithmic scale):
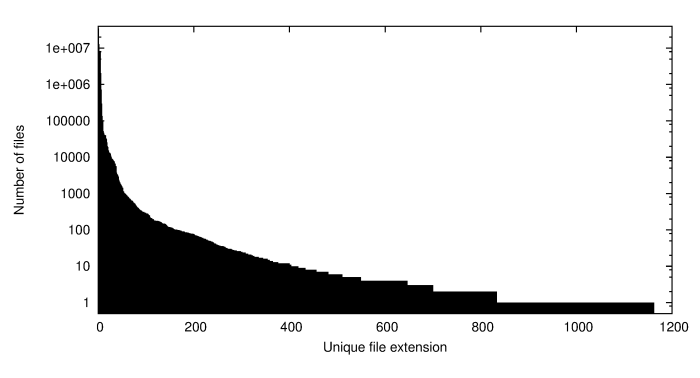
The total number of of unique extensions is no less than 1163. Somewhat surprisingly, .gif turned out to be the most prevalent extension at 34 million files1. Altogether, the 10 most common extensions make up 99% of al files in the e-Depot. There is a long tail of extensions of which less than 10 file objects exist, and these make up for over half of all unique extensions. In the remainder of this blog we will take a closer look at the “top 50” of all file extensions. The full list is too large to include in this blog post, but you can view it as as a table at the following link:
50 most prevalent formats in KB e-Depot by file extension
Analysis of sample dataset
For each extension we extracted about 20 sample files2. We then tried to identify each file with Apache Tika (version 1.4) in detector mode. The third column of our table shows the results for each extension. A manual inspection of selected samples revealed some further details, which are listed in the fourth column of the table (you may need to use the scrollbar at the bottom to view it). One interesting finding was that Matlab Figure files were misidentified by Apache Tika as either application/x-xfig or image/jpeg.
Further analysis of the contents of the 22 ZIP files in our test dataset yielded some additional formats:
| Extension | ID Tika | Remarks |
|---|---|---|
| cif | text/plain | Crystallographic Information File |
| csv | text/csv | Comma-separated values |
| mol | text/plain | MDL Molfile |
| tdb | text/plain | Thermo-Calc Database Format |
| r | text/x-rsrc | R source code |
| m | text/x-objcsrc | Objective-C source code |
Because of the small sample size (and also the fact that the ZIP files were taken from similar batches), these results cannot be taken as representative. Nevertheless, it does show that the identification of scientific text-based data formats such as mol or cif often isn’t very informative. Automatic identification of such formats is difficult anyway, because they typically don’t have unique patterns or header fields.
Accessibility in reading rooms
Finally we wanted to know to what extent the PCs in our reading rooms support our most common formats. To find out, we simply plugged a thumb drive with our test dataset into one of these PCs, and tried to open sample files for each extension in our “top 50” (and those found in the ZIP files as well). To make the results of this exercise easier to digest, we grouped all extensions into 12 format categories. The table below shows the main results for each category:
| Category | Rendering software in reading rooms | Formats accessible in reading rooms? |
|---|---|---|
| Image formats | MS Paint, Windows Photoviewer | Yes |
| Adobe Acrobat | Yes | |
| Web formats | Internet Explorer, Google Chrome | Yes |
| Office formats | Microsoft Office | Yes (support for old Office formats presently not clear) |
| Audio | Windows Media Player, VLC Media Player | No (hardware in reading rooms doesn’t support audio) |
| Video | Windows Media Player, VLC Media Player | Partially (hardware in reading rooms doesn’t support audio) |
| Metadata | Internet Explorer, Notepad, Wordpad | Yes |
| Executables, installers, system files | Not applicable | No |
| Containers | Windows Explorer, 7-Zip | Yes |
| Source code / scripts | Notepad, Wordpad | Partially: available software doesn’t support syntax highlighting |
| (Scientific) text-based data formats | Notepad, Wordpad | Partially: available software doesn’t support syntax highlighting; CSV files are not imported correctly by MS Excel |
| (Scientific) binary data formats | - | No |
The main conclusion is that most formats in our “Top 50” are sufficiently accessible. Nevertheless, there is some room for improvement:
-
The currently installed version of Microsoft Office (2010) does not support all previous versions of some of the Office formats. According to Microsoft’s documentation there’s no support for Powerpoint 95 presentations, and the documentation is not clear on Word 95 and earlier either. From the current analysis we cannot establish whether we have these old formats in our collection, so this may need further work in the future.
-
Comma-delimited text files are not read correctly by Excel. This is caused by region-specific settings of the PCs in the reading rooms, which cause Excel to expect a semicolon as a separator instead of a comma (the comma is used as a decimal separator in Dutch!). This could be improved by changing the configuration of the PCs (but a side-effect would be that semicolon-separated files would then go wrong instead!).
-
The applications that are currently available for the “plain” text formats are not that great for scripts, large data files and files that have non-Windows line endings. This could be easily solved by installing a more sophisticated text editor such as Notepad++.
-
As part of the scientific binary data category, we came across some 1800 Matlab Figure files. This is a proprietary format that requires the Matlab software, which is not available in our reading rooms. So, essentially these files are not accessible to our users. Whether we will take any action on this is a different matter, since Matlab licences are expensive and the number of files is relatively small anyway.
Links
Acknowledgements
Victor van der Wolf prepared the file extension counts; Danny Stephan prepared the database queries for the sample dataset. Barbara Sierman came up with the initial idea of a “file formats top 50”.
Originally published at the KB Research blog

Comments