
Restoring Liesbet's Virtual Home, a digital treasure from the early Dutch web

In 2019, Dutch telecommunications company KPN announced its plans to phase out its subsidiary XS4ALL, which is one of the oldest internet service providers in the Netherlands. With this decision, thousands of homepages and personal web sites that are hosted under the XS4ALL domain are at risk of disappearing forever. The web archiving team of the National Library of the Netherlands (KB) has started an initiative to rescue a selection of these homepages, which includes some of the oldest born-digital publications of the Dutch web. This blog post describes an attempt to rescue and restore one of the oldest and most unique homepages from this collection: Liesbet’s Virtual Home (Liesbet’s Atelier), the personal web site of Dutch Internet pioneer Liesbet Zikkenheimer, which has a history that goes back to 1995. First I give some background information about XS4ALL, and the KB-led rescue initiative. Then I move on to the various (mostly technical) aspects of restoring Liesbet’s Virtual Home. Finally, I address the challenges of capturing the restored site to an ingest-ready WARC file.
XS4ALL
XS4ALL is one of the oldest internet service providers in the Netherlands, and even one of the oldest providers in the whole world. The company was founded in 1993, and has its roots in the Dutch hacker scene. Since its inception, many pioneers of the Dutch internet hosted their homepages under the XS4ALL web domain. Some of these homepages have been online for more than 25 years, and as such they rank among the oldest born-digital publications of the Dutch web. In 2019, parent company KPN (which bought XS4ALL in 1998) announced their intention to phase out the XS4ALL brand. Eventually, all of the company’s services will continue under the KPN brand. This poses an acute threat to much of the (often unique) digital heritage that is hosted under the XS4ALL domain, as in the past a similar situation with provider Euronet resulted in the loss of thousands of early Dutch homepages.
Rescuing the XS4ALL homepages
So, the KB’s web archiving team started an initiative to rescue a selection of the XS4ALL homepages, and add them to the web archive in a special XS4ALL collection. This initiative is supported financially by the SIDN Fund and stichting Internet4all.
Digital treasures
As of May 2020, the KB has selected 3370 homepages for inclusion in XS4ALL collection. Out of the homepages that have been archived so far, 404 are marked as “digital treasures”. These homepages are remarkable because of their age, or because of characteristics that are either unique, or, on the other hand, typical of a particular era or trend.
Liesbet’s Virtual Home
One of these “treasures” is Liesbet’s Virtual Home (in Dutch: Liesbet’s Atelier). This is the old homepage of Liesbet Zikkenheimer, a Dutch Internet pioneer with a background in industrial and graphic design. Her homepage is a “treasure” for several reasons. First of all, it has a history that goes back to 1995, which makes it one of the oldest Dutch homepages that are still available today. Second, Zikkenheimer is an important figure in the history of the Dutch internet. To mention a few examples, in 1997 she developed and published the online version of popular women’s magazine Libelle. She also created web sites for the Margriet and Viva magazines, and developed, published and managed several well-known web portals, most of which were primarily targeted at women. Finally, Liesbet’s Virtual Home is unique because of its structure and design. The site is literally structured like a physical house. Each page represents a particular room, and to get from, say, the living room to the loft, one needs to navigate through a hallway and two flights of stairs. It also has some interactive features that were quite unique at the time of is creation. So, the site meets every possible “digital treasure” criterion.
Problems with the live site
Even though Liesbet’s Virtual Home is still online, several features of the site are no longer working. In particular:
-
The navigation on several pages (including the landing page) is broken, because it is based on server-side image maps that are no longer available.
-
Some interactive features like this bedroom mirror don’t work anymore, because the underlying scripts are missing.
This raised the question whether it would be possible to create a “restored” version of Liesbet’s Virtual Home that has these features working again.
Local copy of site data
After my colleague Kees Teszelszky got in contact with Zikkenheimer, she sent us a ZIP file with a locally stored copy of the site’s directory structure. However, that local copy had several issues as well, and it quickly became obvious it couldn’t be used as a basis for a restored version of the site. However, the ZIP file did contain both the image map files as well as the scripts that are missing from the live site.
Crawling the live site
So, I decided to take the current live site as a starting point. I first tried to crawl and capture the site with this simple Bash script that uses the wget tool. At first sight this seemed to work reasonably well, but a closer inspection revealed that various components of the site were missing. A few examples:
-
The toilet pages are not referenced from their parent pages. This has the result that wget never finds them.
-
Some components are only referenced through Javascript. For example, this page contains the following code that opens a video in a popup window:
<A HREF="javascript:openit('tvplus.mov')">Such items are not picked up by wget, which means they end up missing from the crawl.
Improved crawl
After some experimentation, I was able to improve the crawl by using multiple seed URLs. This means that instead of traversing the site from its index page only, I included both the unreferenced “toilet” pages, as well as a list of all the site’s visible directories and sub-directories (which I could identify from the initial crawl). First I put all of these in a text file (seed-urls.txt):
https://ziklies.home.xs4all.nl/
https://ziklies.home.xs4all.nl/toilet.html
https://ziklies.home.xs4all.nl/e-toilet.html
https://ziklies.home.xs4all.nl/atelier/
https://ziklies.home.xs4all.nl/bad/
https://ziklies.home.xs4all.nl/cas/
https://ziklies.home.xs4all.nl/gambia/
https://ziklies.home.xs4all.nl/keuken/
https://ziklies.home.xs4all.nl/slaapk/
https://ziklies.home.xs4all.nl/slaapk/gspot/
https://ziklies.home.xs4all.nl/toilet/
https://ziklies.home.xs4all.nl/woonk/
https://ziklies.home.xs4all.nl/woonk/agenda/
https://ziklies.home.xs4all.nl/zolder/
I then ran this Bash script, using the above text file as a command-line argument:
scrape-seeds.sh seed-urls.txt
As a check I subsequently did a recursive diff on the output directories of both the original crawl and the improved crawl:
diff -r ./wget-original/ziklies.home.xs4all.nl/ ./wget-improved/ziklies.home.xs4all.nl/ > diff-site-toilet.txt
This showed that the improved crawl contained over 60 files that were not in the original crawl. So, I used the result of this “improved” crawl as a basis for all subsequent restoration steps. In the following sections I will go through the whole restoration process. More details are available in a separate, minimally edited Restoration notes document.
Links to old website domain
Like all old XS4ALL homepages, Liesbet’s Virtual Home was originally hosted as a directory under XS4ALL’s root domain (http://www.xs4all.nl/~ziklies/). At some point XS4ALL gave its customers their own sub-domain (in this case the current address at https://ziklies.home.xs4all.nl/), and redirected any URLs pointing to the “old” location to this sub-domain. Internally, Liesbet’s Virtual Home uses a mixture of relative URLs and absolute ones that still refer to the old location. This causes several issues if the site is hosted locally on a web server. Although it may be possible to remedy these issues using some clever server configuration, I couldn’t quite get this working. I ended up writing a simple Bash script that replaces all references to the “old” location with relative links (which always work, irrespective of the domain).
Audit trail
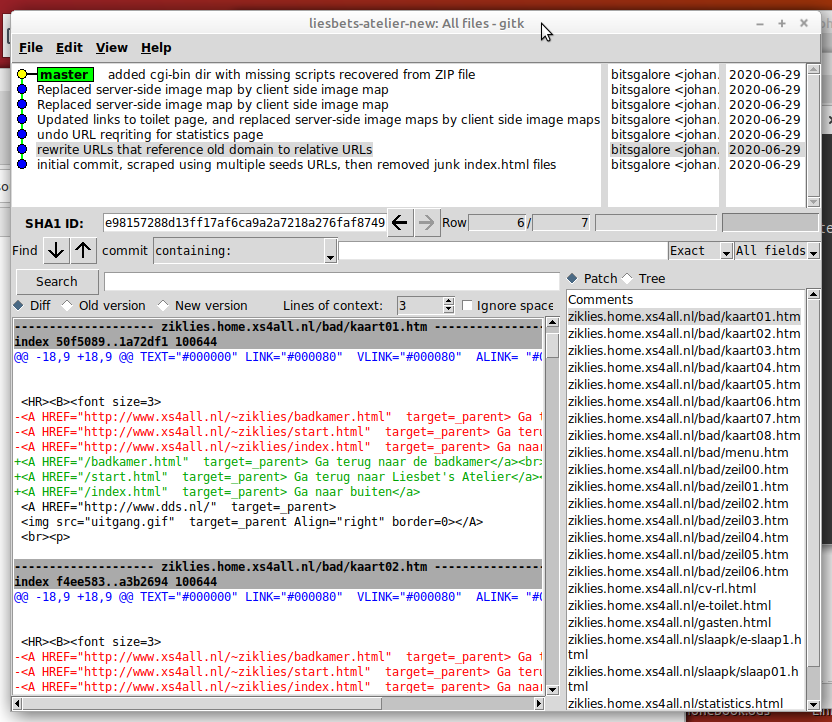
Since a restoration like this involves making changes to a unique digital heritage work, it’s a good idea to record these changes in a verifiable audit trail. To achieve this I simply set up the directory with the crawl as a Git repository, and then created a snapshot (Git commit) for each change. The following screenshot (from the gitk Git repository browser) illustrates this:
-
The upper-left pane lists all snapshots/commits (newest at the top, oldest at the bottom).
-
The lower-left pane shows all changes between the currently selected snapshot and the previous one. In this example, we can see that in file “kaart01.htm” three absolute page references (highlighted in red) were replaced by relative references (highlighted in green).
-
The lower-right pane lists all files that were changed in this snapshot.
This way, the commit history provides a complete audit trail of all changes. It also has the advantage that any changes can be easily undone, if needed. For example, the URL rewriting operation discussed in the previous section had an unintentional side-effect for the statistics page. I could easily revert to the original URLs for this page with 1 single Git command.
Missing links to toilet
As mentioned before, the start.html and e-start.html pages contain erroneous links to the “toilet” pages. Looking at the English-language page:
<B><A HREF="http://imagine.xs4all.nl/ziklies/"> Go to the toilet</a></B>
Here, the URL points to an external domain that doesn’t exist anymore. So, I changed this to:
<B><A HREF="e-toilet.html"> Go to the toilet</a></B>
I applied a similar fix to the Dutch-language page.
Image maps
A number of pages on the site use HTML image maps. An example is the door image on the front page. This is the corresponding HTML source:
<A HREF="/cgi-bin/imagemap/~ziklies/deurtje1.map"><img src="deurtje1.gif" Border=0 ISMAP></A>
This is a server-side image map, where the URL points to an external file (deurtje1.map). However, this file is not available anymore on the live site, which results in a Page Not Found error. Fortunately, I was able to find this file in the ZIP archive provided by Zikkenheimer. Here’s what it looks like:
default http://www.xs4all.nl/~ziklies/start.html
poly http://www.xs4all.nl/~ziklies/start.html 0,56 76,40 91,43 89,67 76,62 6,77 0,60 1,55
poly http://www.xs4all.nl/~ziklies/e-start.html 53,72 80,76 81,81 91,85 89,107 76,106 69,137 42,130 51,77
This shows that the file simply defines areas within the image that are linked to URLs.
From server-side to client-side image maps
Since server-side image maps come with some caveats, I took the liberty of re-implementing the server-side image map with a client-side image map. Both are functionally identical, but client-side image maps are simpler to implement and less likely to break1. Instead of using an external file, a client-side image map is simply an embedded element inside the page, which means we can replace the <A> element in the previous HTML snippet by this:
<img src="deurtje1.gif" usemap="#deurtje1Map" alt="deurtje 1" border="0">
<map name="deurtje1Map">
<area shape="poly" coords="0,56 76,40 91,43 89,67 76,62 6,77 0,60 1,55" href="http://www.xs4all.nl/~ziklies/start.html">
<area shape="poly" coords="53,72 80,76 81,81 91,85 89,107 76,106 69,137 42,130 51,77" href="http://www.xs4all.nl/~ziklies/e-start.html">
<area shape="default" href="http://www.xs4all.nl/~ziklies/start.html">
</map>
Note that the values of the “coords” attributes are identical to the area definitions in the server-side image map. Below is a short video that shows how the restored image map works. Ringing the upper doorbell leads to the Dutch version of the site, whereas the lower doorbell opens the English version.
The site contains 4 more broken server-side image maps. I replaced all of these with client-side image maps in the restored version. For one page the corresponding image map from the ZIP file contained some odd errors, so here I took the image map of the page’s English-language counterpart, and then updated all links accordingly. After these changes the image map navigation is fully functional again.
Interactive bedroom mirror
The bedroom of Liesbet’s Virtual Home features an “interactive mirror”. It is a web form where the visitor can select combinations of clothing, hairstyle and earrings. After clicking on the “have a look into the mirror” button, the selected combination is shown as an image2. However, as the underlying scripts are missing from the live site, it now gives a Page Not Found error. As with the image maps before, the missing (Perl) scripts could be recovered from the ZIP file provided by Zikkenheimer. I added these to a (newly created) “cgi-bin” directory. I also had to make the scripts executable3, and adjust their Shebang strings to a valid interpreter location on my local machine (which, in my case, was different from the location used by the original web server).
The main challenge was then to make the scripts play nicely with a web server. This is beyond the scope of this post, but I created an Apache setup notes document that describes how I made this all work with a local instance of the Apache web server. Amazingly, the script, which is nearly 25 years old, still works perfectly with a modern version of Perl (here Perl 5). The following video gives a brief glimpse of the restored interactive mirror in action:
Interactive toilet door
The toilet page has an interactive feature where visitors can scratch a message onto a virtual toilet door. Zikkenheimer wrote to us that she initially updated the toilet door image by hand (presumably using submissions sent by e-mail), but that she later replaced this with a Python script that automatically updates the image. This script is no longer available from the live site, but it is included in the ZIP file. From a text string, it maps each glyph to a corresponding GIF image, and then pastes these GIF images onto the pre-existing version of the toilet door image, using randomly selected image co-ordinates.
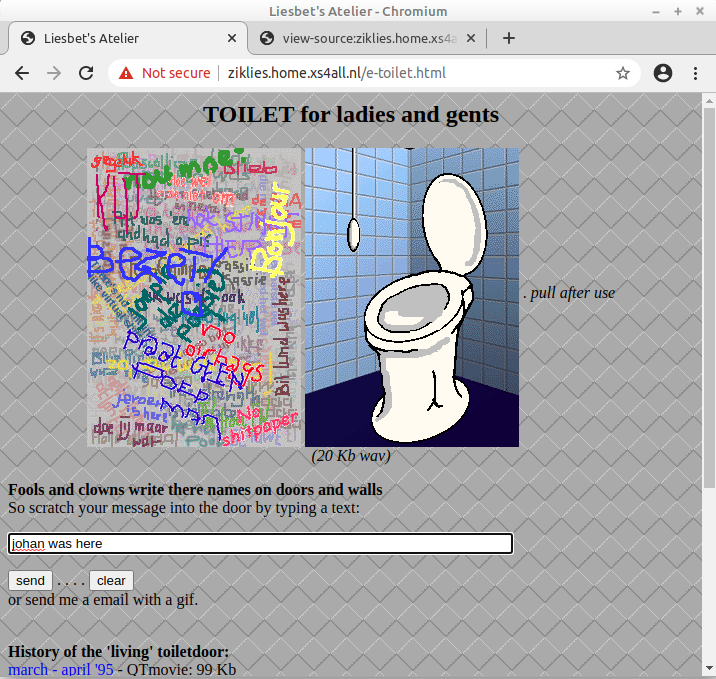
Interestingly, the source of the current “live version” references another script that simply sends the entered message by e-mail4. However, the Python script from the ZIP file shows that the toilet pages were originally hosted at a different server location, and an archived snapshot from the Internet Archive still exists. The source code of that snapshot also contains a link to the Python script.
Restoring the toilet door
I tried to make the interactive toilet door work again, but while doing this I ran into several problems. First of all, the underlying Python script is based on Python 1.4, which was one of the earliest Python releases, and its code is not compatible with modern Python interpreters. I tried to upgrade it to Python-3-compatible code. Overall this was pretty easy, but it uses gdmodule, a Python module that is currently unsupported and not compatible with Python 3. I was able to make the script work with Python 2.7, but since Python 2 is no longer maintained this is not a sustainable solution.
Also, the set of glyph images in the ZIP file appeared to be incomplete, only including lowercase characters (with an image for the “u” glyph strangely missing), and no uppercase characters or punctuation marks. If the user enters any of these missing characters, this results in an “Internal Server Error”. In addition, the script often places text outside of the toilet door image canvas. For both of these issues, it is unclear whether they are specific to the restored version, or simply reflect the state of the old “live” site. Because of these issues, I would not consider the restoration of this part of the site a success.
Unsupported file formats
The site also uses a number of file formats that are not supported by modern browsers. Some examples:
-
The living room features a clickable TV-set that is supposed to open a Quicktime video in a pop-up window. In the latest (77.0.1) version of the Firefox browser, it triggers the following message:
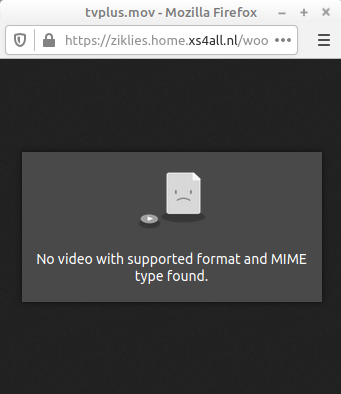
Firefox error message on Quicktime video. In Chromium (83.0.4103.61), the pop-up window is empty, but it does download the file, so it can be played with external media player software.
-
The clickable stereo on the same page links to a Sun Audio file. Depending on the browser used, clicking the link either activates a prompt to play the file in a external player (Firefox), or it is simply downloaded (Chromium)5.
-
This page features an embedded alarm clock in MIDI format, which is also not natively supported by modern web browsers. Chromium does download the file, whereas Firefox appears to ignore it altogether.
-
Last but not least, the bedroom page links to this, which in turn links to an embedded Adobe Shockwave file. Adobe stopped supporting this format in 2019. As a result, the format is no longer supported in web browsers. With no alternative rendering software available, the format is now functionally obsolete.
I haven’t addressed any of these issues in the current restoration attempt. A possible solution would be to use emulation or virtualization to view the site in a late-‘90s web browser6. This may be worth further investigation.
Serving the site
Throughout the restoration process I mostly used Python’s built-in http.server to test any changes I made. This is a lightweight web server that doesn’t require any elaborate configuration, with no need to copy files to reserved locations on the file system. It does have some limitations that make it unsuitable for production use, so for serving the “completed” site I set up and configured an Apache web server instance. This allowed me to have the restored version of Liesbet’s Virtual Home running on my local machine, accessible from its original URL:
The installation and configuration process I followed is described in detail in a separate Apache setup notes document.
WARC capture
Like most web archives, the KB uses the WARC format for storing archived web sites. Since capturing offline web content is a subject I’d been working on earlier as part of the NL-menu rescue operation, I started with this wget-based script, which is a modified version of the script I used for NL-menu. However, the wget crawl didn’t adequately capture the form (and script) behind the interactive bedroom mirror. Some tests with the Webrecorder Desktop App showed that Webrecorder was able to capture individual input combinations, but this required manual input for each combination. With 512 possible combinations, this was not a viable solution, so I needed some way to automate this.
Warcio to the rescue
Happily, several people responded to my request for help on Twitter. Webrecorder author Ilya Kreymer responded I might want to have a look at the warcio library (of which is he is also the lead developer), and, even better, he provided some example code that showed how to do this. For a brief explanation of how this works, have a look at the input form below (for brevity I edited out some of the input choices):
<FORM METHOD="POST"
ACTION="/cgi-bin/barbie1.cgi">
<DL>
<DD><b> First: wich pants or skirt? </b><br>
<INPUT TYPE="radio" NAME="onder" VALUE="1a" > A1
<INPUT TYPE="radio" NAME="onder" VALUE="2a" > A2
::
::
<INPUT TYPE="radio" NAME="onder" VALUE="7a" > A7<br>
</DL>
<br>
<DL>
<DD><b>Second: wich top, sweater or blouse fits? </b><br>
<INPUT TYPE="radio" NAME="midden" VALUE="1b" > B1
<INPUT TYPE="radio" NAME="midden" VALUE="2b" > B2
::
::
<INPUT TYPE="radio" NAME="midden" VALUE="7b" > B7<br>
</DL>
<br>
<DL>
<DD><b>Last: wich earrings and what to do with her hair? </b><br>
<INPUT TYPE="radio" NAME="top" VALUE="1c" > C1
<INPUT TYPE="radio" NAME="top" VALUE="2c" > C2
::
::
<INPUT TYPE="radio" NAME="top" VALUE="7c" > C7<br>
</DL><br>
<center>
<INPUT TYPE="submit" VALUE="have a look into the mirror">
<br></center>
</FORM>
Some key points:
-
The form sets three variables: “onder”, “midden” and “top”. Each of these can have 7 pre-defined values (with ranges [1a, 7a], [1b, 7b] and [1c, 7c], respectively).
-
The data that are entered in the form are sent to the server using a POST request.
With warcio, an individual set of input combinations can be captured like this:
from warcio.capture_http import capture_http
import requests
url = 'http://ziklies.home.xs4all.nl'
warcFile = 'ziklies.home.xs4all.nl.gz'
with capture_http(warcFile):
requests.post(url, data={'onder': '1a', 'midden': '1b', 'top': '1c'})
Note how the data parameter holds a dictionary with the three variables and their associated values. To capture the form’s full behavior, we can simply iterate over all input combinations, and then capture each of them. Having confirmed that this worked, I re-wrote my existing wget-based Bash script into a Python script that only uses warcio. The script is available here. This approach doesn’t work for the interactive toilet door, since, unlike the bedroom mirror, it processes free text, which means that the number of possible inputs is infinite.
Rendering the WARC with Pywb
I finally verified the WARC capture by importing it in Pywb. More details on this can be found in my separate WARC capture and rendering notes. Rendering the WARC did not result in any problems, and to illustrate this, below screenshot shows one output combination of the interactive bedroom mirror:
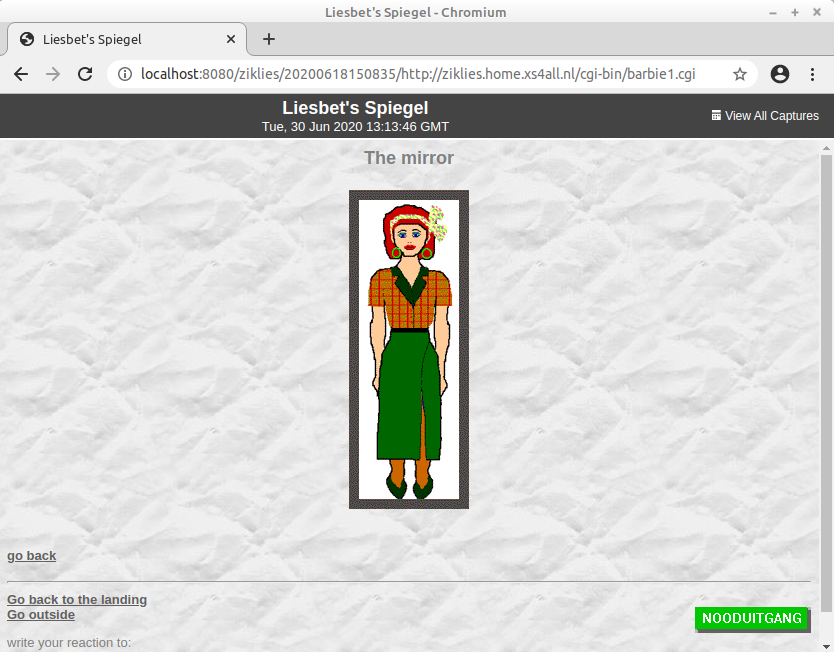
Conclusions
Although none of the procedures described in this blog post are particularly complex, the restoration of Liesbet’s Virtual Home involved a lot of trial and error, which ultimately made it a fairly laborious process. Nevertheless, this effort is justified given the value and historical significance of this homepage. It also involved some decisions that, from an authenticity point of view, are open to criticism. An example is the replacement of the missing server-side image maps by the more modern client-side variety. In any case, the experience gained from this project will also be useful for an upcoming attempt to restore a collection of old corporate websites from source data that we recovered from data tapes last year.
Acknowledgements
I would like to thank Liesbet Zikkenheimer for making the offline data of Liesbet’s Virtual Home available to us for this project. Jak Boumans is thanked for alerting us to this unique homepage, and for establishing the contact with its creator. Ilya Kreymer is thanked for his suggestion on warcio, and more generally for creating the Webrecorder software suite, without which much of this work would simply be impossible. Thanks are also due to Kees Teszelszky. Finally, this work was financially supported by the SIDN Fund and Stichting Internet4all.
Additional resources
Detailed working notes
The following notes provide more details on the restoration steps, the Apache server setup and the WARC capture process, respectively:
Processing scripts
All processing scripts used as part of this work are available here.
More information about the XS4ALL homepages rescue initiative
Below posts (both in Dutch) give some additional background information about the XS4ALL homepages rescue initiative:
Revision history
- 8 July 2020: added sections on toilet door restoration attempt
-
Some purists may consider this a technological anachronism. Client-side image maps were first introduced in HTML 3.2, which was published in 1997, whereas Liesbet’s “what’s new” page shows that most of the site’s development activity took place between early 1995 and late 1997. This could be a problem for users who want to view the site in a period browser (e.g. inside an emulated environment), which may not support client-side image maps. ↩
-
Actually as a composite of 3 images. ↩
-
Under Linux this is simply a matter of issuing a command like
chmod 755 barbie.cgi. ↩ -
Documented here: https://www.xs4all.nl/service/installeren/hosting/mail-a-form-toevoegen/. ↩
-
I’m not actually sure if this behavior was any different on late-‘90s browsers. ↩
-
I did try to open the page using oldweb.today, but none of the browser environments I tried had the necessary Shockwave plugin installed. ↩
-
web-archaeology
- Restoring Liesbet's Virtual Home, a digital treasure from the early Dutch web
- Recovering '90s Data Tapes - Experiences From the KB Web Archaeology project (iPres 2019 paper)
- A simple disk imaging workflow tool
- Roll the tape - recovering '90s data tapes in BitCurator
- Crawling offline web content: the NL-menu case
- Resurrecting the first Dutch web index: NL-menu revisited
-
web-archiving
- How to preserve your personal Twitter archive
- Mapping the Dutch web domain
- Restoring Liesbet's Virtual Home, a digital treasure from the early Dutch web
- Web domain geolocation and spatial analysis with QGIS
- Crawling offline web content: the NL-menu case
- Resurrecting the first Dutch web index: NL-menu revisited
- Dutch newspaper wipes out articles citing fabricated sources - Internet Archive to the rescue!
- Perdiep Ramesar in het Internet Archive
- Demise of the Dutch Blogosphere
- How to save a web page to the Internet Archive

Comments