
Resurrecting the first Dutch web index: NL-menu revisited
NL-menu was the first Dutch web index. The site was originally founded by a consortium of SURFnet, Dutch universities and the KB. From the mid-nineties onwards it was maintained solely by the KB. NL-menu was discontinued in 2004, after which the site was taken offline. In 2006 the domain name was sold to a private company that used it for hosting a web index that was partially based on the original NL-menu site.
Meanwile, the original NL-menu has been largely lost to the mists of time. Even though the Internet Archive’s Wayback Machine contains rather a lot of snapshots of the site, these are incomplete, and don’t capture the original look and feel. For example, this page is a snapshot from June 2002:
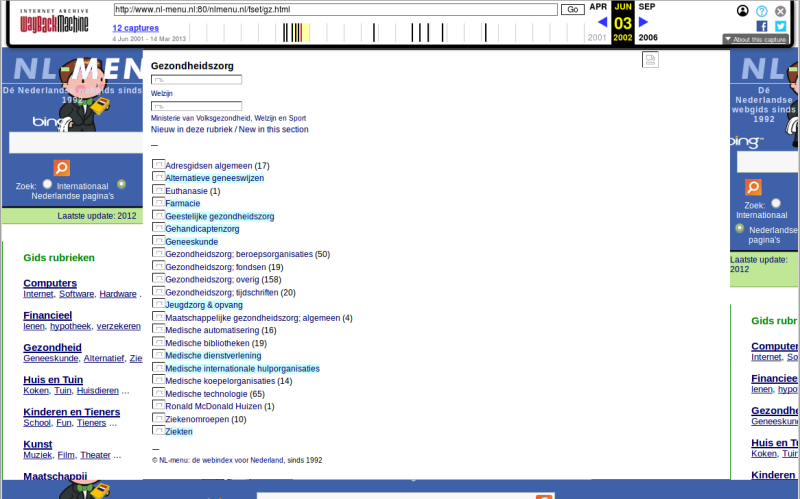
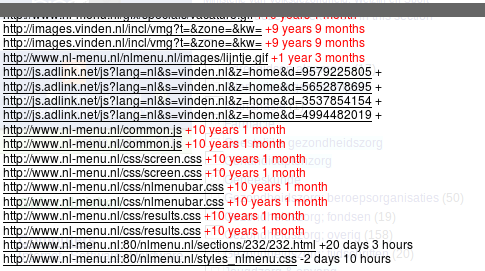
However, this doesn’t look even remotely like the site as it was in 2002. Just for one thing, at the top-left we see a Bing search box, but Bing didn’t even exist until 2009! An inspection of the crawl time stamps (these can be seen by clicking on the top-right About this capture button) reveals that this “snapshot” is really an amalgam of elements that were crawled at wildly varying dates, some as recently as 2018:
NL-menu is not part of the KB Web Archive, as the KB only started its web archiving activities in 2007. The only remaining “complete” copies of NL-menu are three (recordable) CD-ROMs that were burned shortly before the site was taken offline in 2004.
As NL-menu is a unique source of information about the (relatively) early history of the Dutch Internet, we made an attempt at reconstructing the site as it appeared in early 2004. This involved the following steps:
- Recover the data from the remaining CD-ROMs
- Set up a local copy of the site by serving the recovered data om a webserver
- Crawl the recovered site for inclusion in our web archive
The remainder of this blog describes how we went about the first two steps.
Recovering the data
A first attempt at viewing the contents of the CD-ROMs in a file manager resulted in read errors for all discs. This is not surprising, given the instability of CD-Rs, and the fact these discs were burned in early 2004. So, we tried to recover the contents of the discs with the dedicated data-recovery tool ddrescue. We used the following command line:
ddrescue -d -b 2048 -r4 -v /dev/sr0 NL-menu-ddrescue.iso NL-menu-ddrescue.log
Here -d tells ddrescue to read the disc using direct disc access mode, -b sets the block size (which is 2048 bytes for a CD-ROM); -r4 sets the maximum number of retries in case of bad sectors to 4, and -v activates verbose output mode. File NL-menu-ddrescue.iso is the image file with the recovered data; NL-menu-ddrescue.log is a so-called mapfile, which holds information on the recovery status of blocks of data.
One of the advantages of ddrescue is that it can be run multiple consecutive times for each disc, using different optical drives if necessary. This is extremely useful, as it is not uncommon to find that some sectors on a disc result in read errors on one drive, whereas those sectors are read without problems by another drive (and vice versa).
Results of recovery process
Out of the three CD-ROMs, only one copy could be fully recovered without any unreadable sectors. The recovery process required multiple passes with ddrescue, using two computers and four different optical drives (two internal drives, and two external USB drives).
Only half of the second disc could be recovered after a 16-hour recovery pass with ddrescue. An inspection of the resulting ISO image in a hex editor showed the recovered sectors of this disc to be byte-identical to the first disc (which was recovered in full). Having established this, we didn’t do any further attempts at recovering more data from this disc (since it is simply a copy of the first disc).
For the third disc, 99.8% of the data could be recovered after four rounds with ddrescue with four optical drives. Below image shows a visualisation of the recovery process (made with ddrescueview):

Here, each block respresents one 2048-byte sector, where a red block is a sector with read errors. In this case 468 sectors spread across the disc are unreadable. This means that any files or folder definitions that occupy any of those sectors will be damaged. The resulting ISO image turned out to be readable, but one of the top-level directories (which contains half of the files on the disc) is not shown when the image is mounted or opened in an archive manager. So, we discarded this ISO image from any further processing as well. Unfortunately this disc did not turn out to be merely a copy of the first disc.
Inspecting the contents of the ISO image
After mounting the ISO image of the first disc (i.e. the one that was recovered without errors) on a Linux machine, the following directory structure appears:
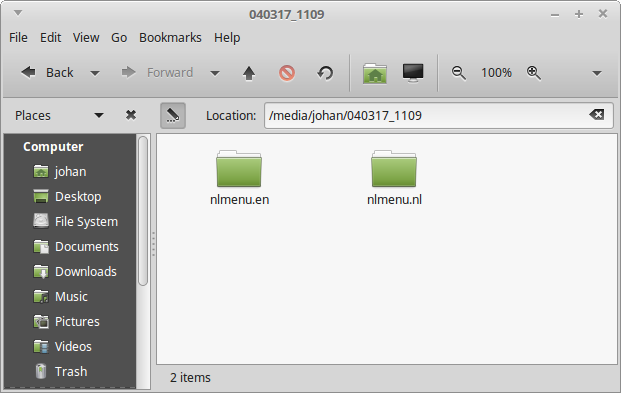
The nlmenu.nl directory contains the Dutch-language version of the site, and nlmenu.en the English-language version (oddly, there’s no top-level index page!). Here are the contents of the nlmenu.nl directory:
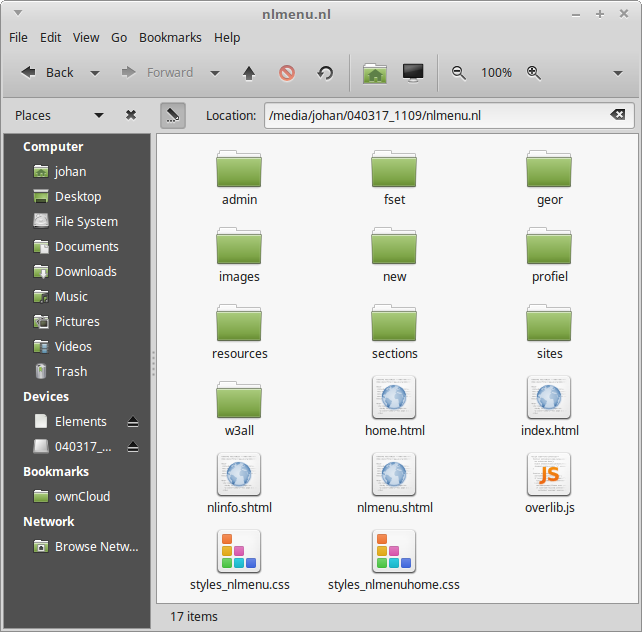
If we open index.html in a browser (Firefox) we see this:

We can see here that several images are not rendered; also none of the (internal) hyperlinks work. This happens because all file paths in the underlying HTML are defined relative to the site’s root directory, and these don’t resolve properly on the local file system. In order to render the site correctly we have to serve it from a locally installed web server.
Serving the CD-ROM contents with a web server
So, we installed the Apache web server on a Linux machine, and then configured it to serve the unpacked contents of the ISO image. More details on how we did this can be found in these technical notes. Configuring the hosts file (as explained in the technical notes) allowed us to render the site on localhost from its original URL:
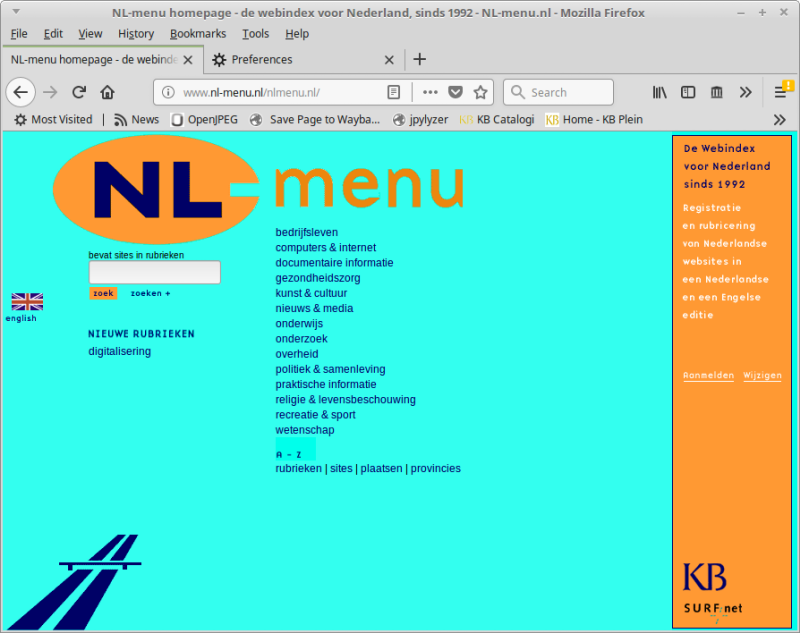
We could crawl the resurrected site with Heritrix for inclusion in our web archive, but before doing this a number of authenticity-related issues need to be sorted out first. For one thing, we need to record metadata that makes it absolutely clear that our archival snapshot was taken from a locally reconstructed copy, rather than the original site. Also, it’s not completely straightfoward how the archiving date should be defined (is this 2004 ore 2018?). We’d be very interested to hear how other web archives are dealing with these issues.
Publicly available version of the recovered site
The KB web archive is only accessible on-site in our reading rooms. Since the KB owns the rights to NL-menu, we decided to make the reconstructed site available on the KB Research website. In order to make this work, we applied a couple of small changes to the original files:
- Relative references to website resources were re-written to reflect the location of the site on the kbresearch domain.
- All references to the original nl-menu.nl domain were updated to the kbrearch.nl domain (most importantly this prevents JavaScript-triggered redirects to the original live nl-menu.nl domain).
- The Dutch index page was copied to the site root, so that it’s used as a top-level index (this was done because the CD-ROM has no top-level index page).
The above changes were all made using this script.
The result of all this is available here:
http://www.kbresearch.nl/nl-menu/nl-menu/
This reflects the state of NL-menu briefly before it closed down in 2004.
Although at first glance the reconstructed site appears to be of much better quality than any of the available Wayback snaphots, there are a couple of caveats:
- Links to categories that contain sub categories don’t work in Firefox. A workaround is to right-click on the link and open it in a new tab (or disable JavaScript). In Chrome/Chromium these links work normally.
- The site contains a number of forms that don’t work because the associated CGI scripts are missing (these scripts are not on the CD-ROM).
- Some pages show the URL http://www.kbresearch.nl, instead of the original http://www.nl-menu.nl. This is an unintended side-effect of the script that was used to update the links.
There may be more issues; please feel free to contact us if you spot anything that doesn’t look quite right!
Acknowledgements
Thanks are due to the folllowing people for their advice and suggestions: Annemarie Beunen, Willem Jan Faber, Kees Teszelszky, and Lammert Zwaagstra.
Additional resources
- NL-menu (2004 snapshot at kbresearch.nl)
- Serving a static website with the Apache web server (technical notes)
- How can we improve our web collection? An evaluation of web archiving at the KB National Library of the Netherlands (2007-2017)
Originally published at the Open Preservation Foundation blog
-
optical-media
- Identification of physical storage media and devices with Python and the Windows API
- Introducing Isolyzer 1.4
- Offline digital data carriers in the KB deposit collection
- A simple workflow tool for imaging optical media using readom and ddrescue
- Resurrecting the first Dutch web index: NL-menu revisited
- Update on Isolyzer: UDF, HFS+ and more!
- Image and Rip Optical Media Like A Boss!
- Imaging CD-Extra / Blue Book discs
- Detecting broken ISO images: introducing Isolyzer
- Breaking WAVEs (and some FLACs too)
- Preserving optical media from the command-line
-
web-archaeology
- Restoring Liesbet's Virtual Home, a digital treasure from the early Dutch web
- Recovering '90s Data Tapes - Experiences From the KB Web Archaeology project (iPres 2019 paper)
- A simple disk imaging workflow tool
- Roll the tape - recovering '90s data tapes in BitCurator
- Crawling offline web content: the NL-menu case
- Resurrecting the first Dutch web index: NL-menu revisited
-
web-archiving
- How to preserve your personal Twitter archive
- Mapping the Dutch web domain
- Restoring Liesbet's Virtual Home, a digital treasure from the early Dutch web
- Web domain geolocation and spatial analysis with QGIS
- Crawling offline web content: the NL-menu case
- Resurrecting the first Dutch web index: NL-menu revisited
- Dutch newspaper wipes out articles citing fabricated sources - Internet Archive to the rescue!
- Perdiep Ramesar in het Internet Archive
- Demise of the Dutch Blogosphere
- How to save a web page to the Internet Archive

Comments