
How to preserve your personal Twitter archive

As a total collapse of Twitter is becoming more likely every day, many Twitter users have started to archive their personal data from the platform while it still exists. Twitter allows you to request and download your personal archive. Even though this works well, and the quality of the archive is surpringly good, it does have some shortcomings. The result of these shortcomings will be that some information in the archive (e.g. on followed accounts and followers) will be lost once Twitter ceases to exist. Some other information (in particular full, unshortened URLs) is included in the archive, but it is not easily accessible from the main HTML interface. The good news is, that some excellent tools exist to fix these shortcomings.
In this post I outline the workflow I used to preserve my own Twitter archive, and while doing so I also provide some background information on the shortcomings of the Twitter archive. Since some of these steps may, at first sight, be a little daunting for less tech-savvy readers, I’ve tried to provide step-by-step instructions where possible.
Disclaimer
First a little disclaimer: I don’t want to suggest that what follows is the “best”, “proper” or even a “good” way to do this. For most of the issues I’m addressing here, several alternatives exist, and some may be better than what I’m suggesting here. Also, an in-depth analysis of the Twitter archive, and a comparison of different tools and approaches are both beyond the scope of this post (besides I don’t have the time for this). Ultimately, all I’m describing here is a workflow that, for now, looks “good enough” for my own purposes. I’m sharing it here because I think it will be “good enough” for many others as well, or at least provide a reasonable starting point. With that said, I can’t give any guarantees here, so keep this in mind while reading what follows!
Request and download Twitter archive
Most importantly, you need to request and download your Twitter data1. The basic steps are:
- While logged in to Twitter, go to your account’s settings.
- Click on “Download an archive of your data”, and then simply follow the instructions.
- Twitter will issue a notification when the archive is ready:
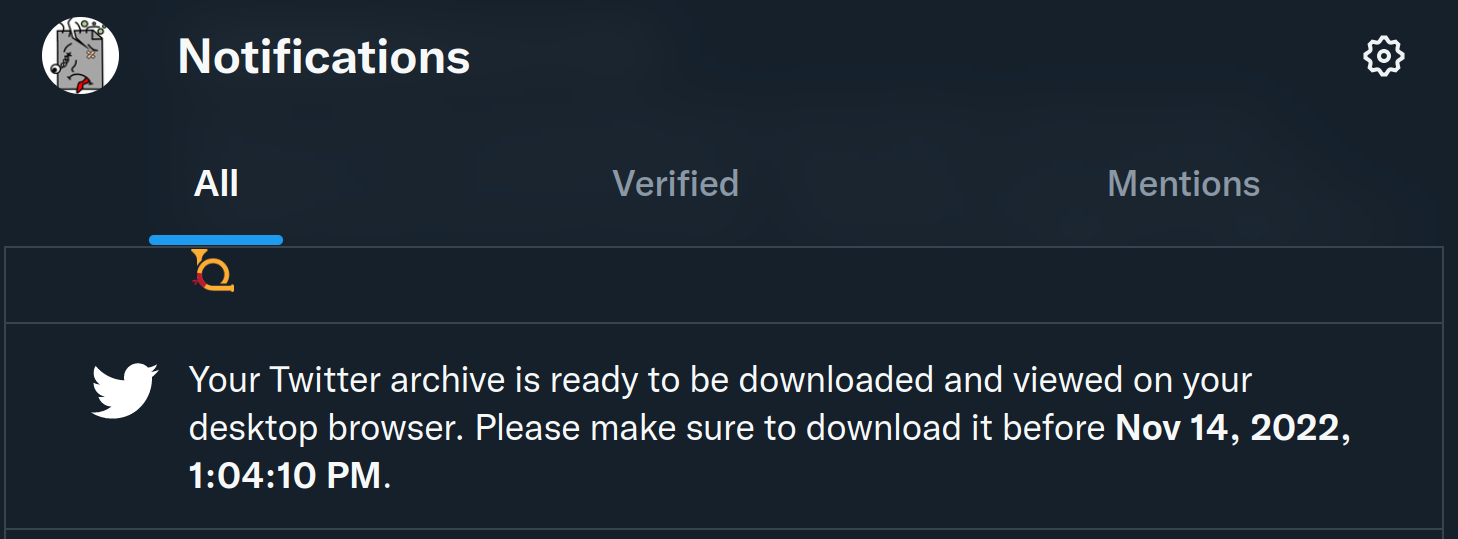 This may take a while. When I did this two weeks ago, I had to wait over 24 hours; various people have told me that currently it take several days. Once ready, you can download the archive as one large ZIP file.
This may take a while. When I did this two weeks ago, I had to wait over 24 hours; various people have told me that currently it take several days. Once ready, you can download the archive as one large ZIP file. - Once downloaded, unzip the file to a folder.
Shortcomings of the Twitter archive
As several people have pointed out before, the archive data provided by Twitter have a number of shortcomings. Below a (probably incomplete) overview of the most obvious ones.
Shortened t.co links
Perhaps most importantly, if you access your Twitter archive from your web browser by opening the “Your archive.html” file, any clickable hyperlinks you see are shortened t.co links that use Twitter’s link shortener service:
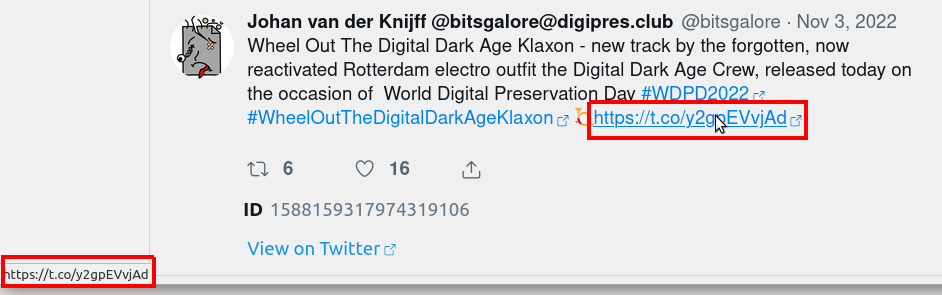
These links will stop working once Twitter goes down. The original, unshortened links are actually stored in the underlying JSON data that are part of the archive (file “tweets.js” in the “data” folder). For example, here’s the full data from the Tweet in that screenshot. Let’s zoom in on its “urls” attribute:
"urls" : [
{
"url" : "https://t.co/y2gpEVvjAd",
"expanded_url" : "https://youtu.be/C47ZCosJPAw",
"display_url" : "youtu.be/C47ZCosJPAw",
"indices" : [
"246",
"269"
]
}
]
As you can see, the “urls” attribute contains both a shortened t.co link (“url”), the unshortened link (“expanded_url”), and a display link (“display_url”). So all the data are there, but the unshortened links just aren’t accessible from the archive’s web interface.
Full-size images
The Twitter archive only contains downscaled versions of posted images. Clicking on an image to expand it takes you to the live Twitter website. Again, this is something that will stop working once Twitter is gone.
Twitter network data
Although the Twitter archive does contain files with the accounts that you follow and the accounts that follow you, these are given as numerical identifiers that will most likely be meaningless if Twitter disappears. Here’s an example:
{
"following" : {
"accountId" : "216697909",
"userLink" : "https://twitter.com/intent/user?user_id=216697909"
}
}
Here, the user link with account ID 216697909 (https://twitter.com/intent/user?user_id=216697909) resolves to the account of the Open Preservation Foundation. Once Twitter is gone, this user link will stop resolving, which will make it very hard to figure out which actual person or organization was associated with it.
Fortunately, some excellent solutions exist that can fix most of the above shortcomings, and they are pretty easy to use as well. Let’s start with addressing the network data issue, as this is something you can do immediately, without having to wait for your Twitter archive.
Preserve your Twitter network with FediFinder
FediFinder is an online tool written by Luca Hammer. Its main purpose is to find Fediverse accounts that correspond to your Twitter connections. However, it also works great for tracking your entire Twitter network, including your followers, accounts that you follow, and list members.
Just follow these steps:
-
While you’re logged into your Twitter account, go to https://fedifinder.glitch.me/
-
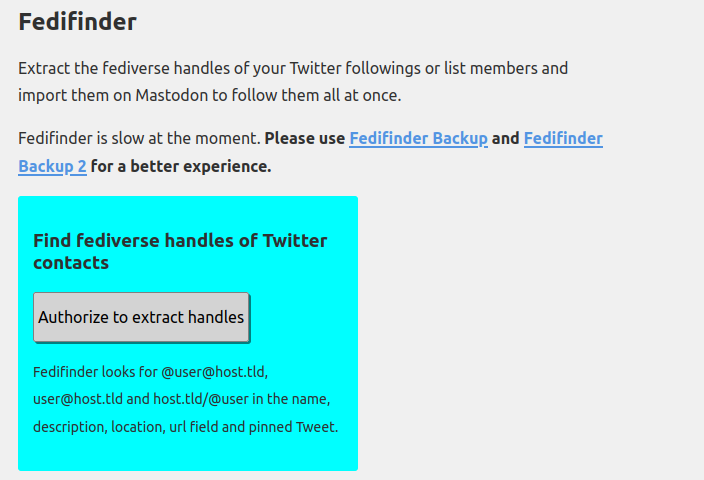
Click on the “Authorize to extract handles” button (this will give FediFinder read permissions to your Twitter account):
-
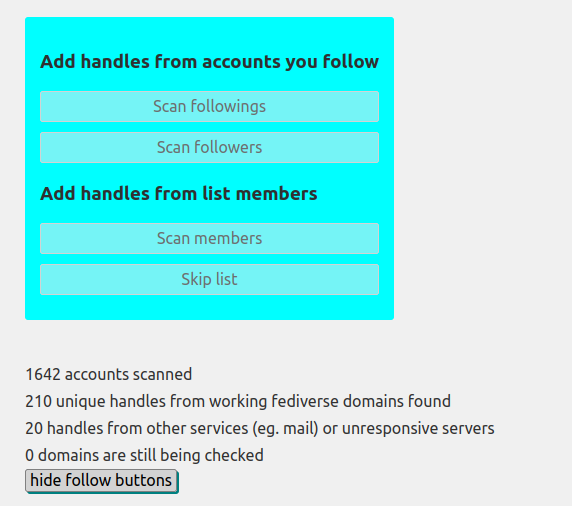
In the page that appears, click on “Scan followings”, “Scan followers” and “Load lists”. For each list, click on “Scan members”. If all goes well you’ll see something like this:
-
Scroll past the list of search results to the bottom of the page, and click on the small “accounts.csv” link2:
Once downloaded, you can open the file in any spreadsheet software. For each account, it contains the Twitter user name, the real name, any lists of which the account is a member, associated Fediverse handles, the account’s location, and its profile description.
Optionally, afterwards you may want to remove FediFinder from your Twitter account’s connected app list using this link:
Improve archive with Twitter archive parser
Tim Hutton has written twitter-archive-parser, which is a Python tool that fixes most of the remaining issues, and some other issues as well3. Most importantly, it creates both HTML and Markdown versions of the archive, with all shortened t.co URLs replaced with their original versions. Optionally, it can also be instructed to download full-size versions of images4.
To use it, follow these steps:
-
Install Python 3 on your system if you don’t have it already. If you’re a Windows user and you’re not sure how to do this, check out Alberto Pettarin’s easy to follow instructions.
-
Then download the twitter-archive-parser script. For this, just right-click this link, select “Save link as”, and save the file into the folder where you extracted the archive5.
-
Start a command-prompt or terminal, and change the working directory to the folder where you extracted the archive. Windows users may want to have another look at Alberto Pettarin’s explainer, in particular the “Using The Command Prompt” and “Changing The Working Directory” sections.
-
Run the twitter-archive-parser script from the command-prompt or terminal, using the following command:
python parser.pyDepending on your operating system, you may need to replace “python” with “python3”:
python3 parser.pyThe script will most likely ask you to confirm the installation of one or two Python modules (“requests” and “imagesize”); if this happens, just type “y” and press the Enter key.
-
Finally, the script will ask if you want to download original-size images. Type “y” if you want this, or “n” if not. Note that downloading the images can take quite a bit of time (depending on the size of your Twitter archive, and the number of images and multimedia it contains).
As an aside, I noticed that archive parser was unable to download some images. I don’t particularly care about this myself, but if images are crucially important to you, the “media” folder contains a download log (file “download_log.txt”) with full details of the download status of each image.
And that’s all there is to it!
Alternative approaches and variations
As I already mentioned in the introduction, I’m not making any claims that the above steps are the “proper” way to do this, and various alternative approaches exist. In this section I’ll highlight a few of these.
After I published the first draft of this post, I found this earlier post by Jeroen Wiert Pluimers. This describes an overall workflow that is similar to the one described here (it also uses archive parser), but adds the extraction of alt-text image descriptions, exporting of bookmarks, and archiving of t.co URL shortener links to the the Wayback Machine.
Ed Summers has written an alternative t.co unshortener, which is explained in this blog post. Ed has also written this post on archiving Twitter bookmarks, which are not included in the archive data. And here’s a Ruby script by Ryan Baumann that exports your Twitter Bookmarks to JSON (note that the scripts deletes the original bookmarks to get around API limits). As I never use bookmarks, I’m not really interested in this myself, but this might be important to some users.
Mike Hucka’s Taupe tool extracts URLs from tweets, retweets, replies, quote tweets, and “likes” from a personal Twitter archive, and writes these to a comma-delimited text file. This is especially useful if you want to preserve linked resources (e.g. by sending them to a web archive).
Tweetback is an open-source software project by Zach Leatherman that creates a static website from your Twitter archive. See this blog post for more information about it, as well as some links to static websites that were created with it. This looks like a really interesting option for those who want to publish their Twitter archive.
Twitter-nest is a set of tools by S. Qiouyi Lu that allow you to create a decentralized Twitter clone on WordPress.
Internet Archive has also made it possible to upload your Twitter archive to its Wayback Machine. See this article for instructions.
Finally this TechCrunch feature mentions some more tools that might be worth perusing.
Final thoughts
It’s good to keep in mind that the development of tools like archive parser currently moves at a pretty fast pace. Just as an example, when I ran archive parser only yesterday (19th of November), it wasn’t able to report Twitter followers and followings, whereas this functionality is included in the latest (20th of November) release. So I expect these tools will become even better over time (but don’t wait for it, as there’s a real chance that Twitter may be gone by then!).
Please feel free to use the comment section to post links to alternative tools or methods, or if you spot any glaring errors in this post.
Additional links and resources
-
Twitter archive parser (“related tools” section lists some more more tools that might be useful)
-
A step-by-step guide on installing Python and using the Command Prompt for Windows
-
Ryan Baumann - Exporting As Many of Your Twitter Bookmarks As Possible
-
Ruby script by Ryan Baumann that exports Twitter bookmarks to JSON (this also deletes the original bookmarks to get around API limits, so use with caution!)
-
Quit Twitter better with these free tools that make archiving a breeze (TechCrunch)
Revision history
-
21 November 2022: updated info about Twitter’s notification when the archive download is ready.
-
21 November 2022: added references to Ryan Baumann’s bookmarks export script.
-
21 November 2022: added references to earlier blog post by Jeroen Wiert Pluimers.
-
22 November 2022: added references to Taupe tool by Mike Hucka.
-
23 November 2022: added references to TechCrunch feature.
-
29 November 2022: added references to Tweetback.
-
1 December 2022: added references to Twitter-nest.
-
15 December 2022: added references to Wayback archiving; renamed and re-strucured final sections.
-
More details can be found here, although some of the info looks slightly out of date. ↩
-
The large “Export fedifinder_accounts.csv” link will give you a file that only includes Fediverse accounts. This can be useful for automating your follows on Mastodon, but if you want detailed information on all Twitter accounts you (also) need to use the small link! ↩
-
Among other things, it also fixes some issues with Direct Messages, which by default don’t include user handles. ↩
-
The version of Archive parser I used wasn’t able to produce lists of followers and followings. More recent versions (20 November 2022 an onward) do have this functionality, but the output is less detailed than FediFinder. Also, it doesn’t distinguish between direct follows and follows through a list. So it’s probably a good idea to use FediFinder for this. ↩
-
The name of this folder looks something like this:
“twitter-2022-11-07-2366bc80316…4e7b77”. ↩
-
web-archiving
- How to preserve your personal Twitter archive
- Mapping the Dutch web domain
- Restoring Liesbet's Virtual Home, a digital treasure from the early Dutch web
- Web domain geolocation and spatial analysis with QGIS
- Crawling offline web content: the NL-menu case
- Resurrecting the first Dutch web index: NL-menu revisited
- Dutch newspaper wipes out articles citing fabricated sources - Internet Archive to the rescue!
- Perdiep Ramesar in het Internet Archive
- Demise of the Dutch Blogosphere
- How to save a web page to the Internet Archive

Comments