
Why PDF/A validation matters, even if you don't have PDF/A - Part 2
This is the second and final instalment of a 2-part blog on the use of PDF/A validators for identifying preservation risks in PDF. You can read the first part here. In Part 1 I showed how PDF/A validators can be used to identify preservation risks in a PDF. I illustrated this with an example that uses the PDF/A validator component of Adobe Acrobat’s Preflight tool. Needless to say, Acrobat is not scalabe to situations where you need to verify large volumes of PDFs. Luckily, several stand-alone PDF/A validators exist that are designed especially to do just that.
Apache Preflight
During the SCAPE project we did a number of experiments with the PDF/A validator that is part of the open-source Apache PDFBox library (incidentally it is also called Preflight). Throwing the PDF of our last example at Apache Preflight results in the following output1:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<preflight name="Jpeg_linked.pdf">
<executionTimeMS>9792</executionTimeMS>
<isValid type="PDF/A1-b">false</isValid>
<errors count="96">
<error count="1">
<code>3.1.3</code>
<details>Invalid Font definition, CourierNewPSMT: FontFile entry is missing from FontDescriptor</details>
</error>
<error count="1">
<code>7.11</code>
<details>Error on MetaData, PDF/A identification schema http://www.aiim.org/pdfa/ns/id/ is missing</details>
</error>
<error count="3">
<code>6.2.1</code>
<details>Action is forbidden, GoToPage isn't authorized as named action</details>
<page>0</page>
</error>
::
::
<error count="1">
<code>1.4.2</code>
<details>Trailer Syntax error, The trailer dictionary contains Encrypt</details>
</error>
</errors>
</preflight>
Assessment against a technical profile / policy
By post-processing Preflight’s XML output further, it is possible to automatically evaluate PDFs against a user-defined set of features (i.e. a technical profile, equivalent to what was known as a control policy in the SCAPE project). This is pretty straightforward if you express all features (or policy elements) as Schematron rules. Here’s an example of a Schematron rule that checks for encryption:
<?xml version="1.0"?>
<!--
Schematron rules for policy-based validation of PDF, based on output of Apache Preflight.
-->
<s:schema xmlns:s="http://purl.oclc.org/dsdl/schematron">
<s:pattern name="Checks for encryption">
<s:rule context="/preflight/errors/error">
<s:assert test="not(code = '1.0' and contains(details,'password'))">Open password</s:assert>
<s:assert test="not(code = '1.4.2')">Encryption</s:assert>
</s:rule>
</s:pattern>
</s:schema>
Rules can be defined for other features as well (e.g. multimedia, fonts), which makes it possible to test against custom policies. The figure below illustrates the general procedure:
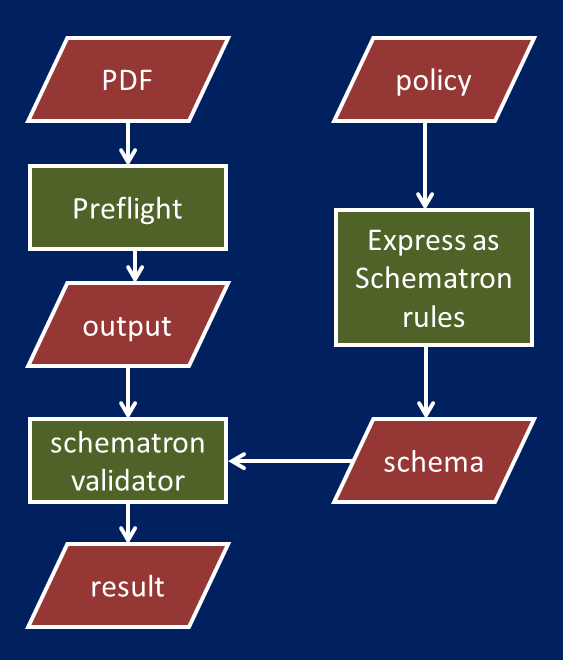
A simple demo (based on Shellscript) that implements the above workflow can be found here.
Test with Govdocs1 corpus
As part of the SCAPE work, we tested whether we could use Preflight in this way to assess a large set of PDFs. For this we used about 15,000 PDFs from the Govdocs1 corpus. We tried to assess these PDFs against a user-defined policy, which was made up of the following elements:
- No encryption or password protection
- Fonts must be embedded and complete
- No JavaScript
- No embedded files (i.e. file attachments)
- No multimedia content (audio, video, 3-D objects)
- File should be valid PDF2.
The somewhat disappointing result of this exercise was that only 26% of all PDFs in the dataset satisfied all criteria in our test policy! Closer inspection of the Preflight output showed the majority of validation errors that caused this to be related to fonts. Preflight is able to report on many different font-related errors, but their exact meaning is not always clear, and neither is their impact on the rendering process. This made it difficult to establish whether the results reflected the quality of the PDFs, or perhaps our assessment was too strict on font errors.
Way forward: VeraPDF
The original report on the Govdocs1 analysis ended with the following conclusions:
These preliminary results show that policy-based assessment of PDF is possible using a combination of Apache Preflight and Schematron. However, dealing with font issues appears to be a particular challenge. Also, the lack of reliable tools to test for overall conformity to PDF (e.g. ISO 32000) is still a major limitation. Another limitation of this analysis is the lack of ground truth, which makes it difficult to assess the accuracy of the results.
Earlier this year work started on VeraPDF, an open-source PDF/A validator that -like Preflight- will be part of the PDFBox library. Its development is funded by the EU PREFORMA project. The consortium that is behind the software includes the PDF Association, whose member base covers a wide spectrum of vendors that already implement PDF technology. Although still in its early stages, it’s interesting to see how the VeraPDF work could help in solving the issues that we identified as part of the SCAPE work.
Font issues
As I’m writing this, font checks haven’t been implemented yet in the VeraPDF code. Nevertheless, validation profiles already exist for a number of aspects of PDF/A. These profiles contain one or more validation rules, and each rule explicitly references its corresponding clause in the PDF/A standard. For example, have a look at this rule on images:
<?xml version="1.0" encoding="UTF-8"?>
<profile xmlns="http://www.verapdf.org/ValidationProfile" model="org.verapdf.model.PDFA1a">
<name>ISO 19005-1:2005 - 6.2.4 Images - Alternates</name>
<description></description>
<creator>veraPDF Consortium</creator>
<created>2015-06-16T22:22:45Z</created>
<hash>sha-1 hash code</hash>
<rules>
<rule id="6-2-4-t01" object="PDXImage">
<description>An Image dictionary shall not contain the Alternates key</description>
<test>Alternates_size == 0</test>
<error>
<message>Alternates key is present in the Image dictionary(</message>
</error>
<reference>
<specification>ISO19005-1</specification>
<clause>6.2.4</clause>
</reference>
</rule>
</rules>
</profile>
Here, the fields in the clause field in the reference element refers to a specific clause in the PDF/A-1 (ISO 19005-1) specification. This makes the errors much easier to interpret, since they are directly linked to the standard. I expect that this will make the interpretation of font-related errors much clearer as well.
Conformance to canonical PDF
A PDF may satisfy all requirements of PDF/A, and still be broken. An example is file veraPDFHiResWrongObjectID.pdf. If you open it in Acrobat you will see this:
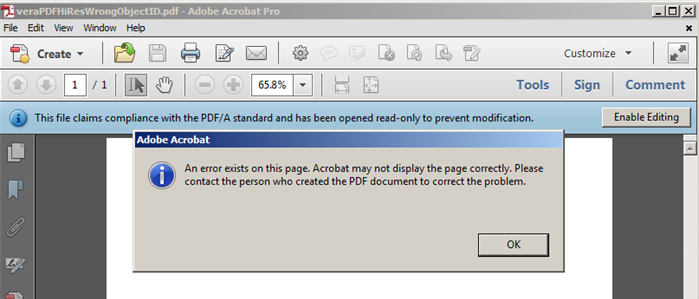
Neverheless, Apache Preflight considers this to be “valid” PDF/A:
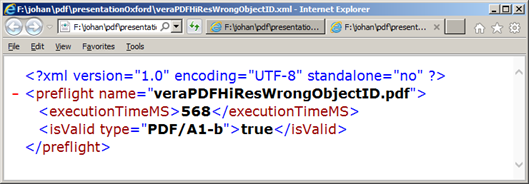
The reason for this is that the structure of this file is broken at a deeper level than the (relatively high-level) PDF/A profiles3. Although the current funding for VeraPDF only addresses PDF/A, the veraPDF Technical and Functional Specification stresses that its validation model is extensible, and this would ultimately allow more elaborate validation. From p. 16 of the document:
The veraPDF model encourages plug-ins for parsing not only PDF/A-related third-party data structures (…), but also for other features in ISO 32000, other ISO standards for PDF such as PDF/E or PRC, images, and for embedded content such as rich media or attachments (…)
This suggests that ultimately, VeraPDF has the potential to develop into a full-fledged canonical (ISO 32000) PDF validator. Obviously this would be a huge task that would require substantial additional effort and funding, but it’s encouraging to see that the overall design already allows for such a move.
Ground truth
During the SCAPE project we often struggled to find suitable openly licensed test files. In fact, for much of the policy-based assessment work we relied on files on the Adobe Acrobat Engineering website, which is a true treasure trove of PDFs with exotic features. Or rather was, as the site’s been offline for at least several weeks now, and it’s unclear when (if?) it will be back4. Back in 2013, the BL’s Andy Jackson already inquired about the license terms of those files, and Adobe’s response was that although the files were free to use, redistribution was not allowed. Fast-forward two years, and the files are gone! Internet Archive has several snapshots of the site, but they are incomplete and do not include all sample files.
This poignantly illustrates the importance of test data that are available under a sufficiently open license that allows redistribution. I’m happy to see that the VeraPDF initiative includes work on the production a number of openly-licensed test corpora (see also sections CE 3.2 and TS 6.2 of the Technical and Functional Specification).
Conclusion
In this blog series I’ve given a brief overview of some preservation risks of the PDF format, and I showed how PDF/A validators can be used to identify such risks, even in files that are not really PDF/A. I also explained the main problems we encountered while trying to use the open-source Apache Preflight PDF/A validator to identify preservation risks in a large collection of PDFs. The new VeraPDF initiative is still in its early stages, but it appears to be addressing most of these issues. Therefore it would be interesting to apply it to some of the datasets that we used for SCAPE, once the software is more fully developed.
Further resources
-
Why PDF/A validation matters, even if you don’t have PDF/A (Part 1)
-
Portable Document Format in the OPF File Format Risk Registry
Originally published at the Open Preservation Foundation blog
-
This is only an extract from the complete output file, which is much larger. ↩
-
Preflight does not perform canonical PDF validation, but it does do some additional checks beyond PDF/A, hence the “should” rather than “must”. ↩
-
More precisely, I deliberately changed the object reference to an image to a nonsense value. Incidentally, Acrobat Preflight does detect this error, which means that it checks at least some aspects of canonical PDF. ↩
-
Adobe’s web team are aware of the issue, but it’s not clear when the site will be back (if at all) ↩
-
Apache-Preflight
- Why PDF/A validation matters, even if you don't have PDF/A - Part 2
- Identification of PDF preservation risks: analysis of Govdocs selected corpus
- Identification of PDF preservation risks with Apache Preflight: the sequel
- Identification of PDF preservation risks with Apache Preflight: a first impression
-
PDF
- PDF Quality assessment for digitisation batches with Python, PyMuPDF and Pillow
- Escape from the phantom of the PDF
- VeraPDF parse status as a proxy for PDF rendering: experiments with the Synthetic PDF Testset
- Identification of PDF preservation risks with VeraPDF and JHOVE
- On The Significant Properties of Spreadsheets
- PDF processing and analysis with open-source tools
- Policy-based assessment with VeraPDF - a first impression
- PDF/A as a preferred, sustainable format for spreadsheets?
- Why PDF/A validation matters, even if you don't have PDF/A - Part 2
- Why PDF/A validation matters, even if you don't have PDF/A
- When (not) to migrate a PDF to PDF/A
- Identification of PDF preservation risks: analysis of Govdocs selected corpus
- Identification of PDF preservation risks with Apache Preflight: the sequel
- What do we mean by "embedded" files in PDF?
- Identification of PDF preservation risks with Apache Preflight: a first impression
- PDF – Inventory of long-term preservation risks
-
preservation-risks
- Escape from the phantom of the PDF
- Multi-image TIFFs, subfiles and image file directories
- Identification of PDF preservation risks with VeraPDF and JHOVE
- On The Significant Properties of Spreadsheets
- PDF processing and analysis with open-source tools
- ISO/IEC TS 22424 standard on EPUB3 preservation
- Does Microsoft OneDrive export large ZIP files that are corrupt?
- Why PDF/A validation matters, even if you don't have PDF/A - Part 2
- Why PDF/A validation matters, even if you don't have PDF/A
- Measuring Bigfoot
- Assessing file format risks: searching for Bigfoot?
- PDF – Inventory of long-term preservation risks
- EPUB for archival preservation
-
schematron
- PDF Quality assessment for digitisation batches with Python, PyMuPDF and Pillow
- Policy-based assessment with VeraPDF - a first impression
- Why PDF/A validation matters, even if you don't have PDF/A - Part 2
- Policy-based assessment of EPUB with Epubcheck
- Automated assessment of JP2 against a technical profile
-
VeraPDF
- Escape from the phantom of the PDF
- VeraPDF parse status as a proxy for PDF rendering: experiments with the Synthetic PDF Testset
- Identification of PDF preservation risks with VeraPDF and JHOVE
- PDF processing and analysis with open-source tools
- Policy-based assessment with VeraPDF - a first impression
- Why PDF/A validation matters, even if you don't have PDF/A - Part 2
- Why PDF/A validation matters, even if you don't have PDF/A

{kind=link}
Comments