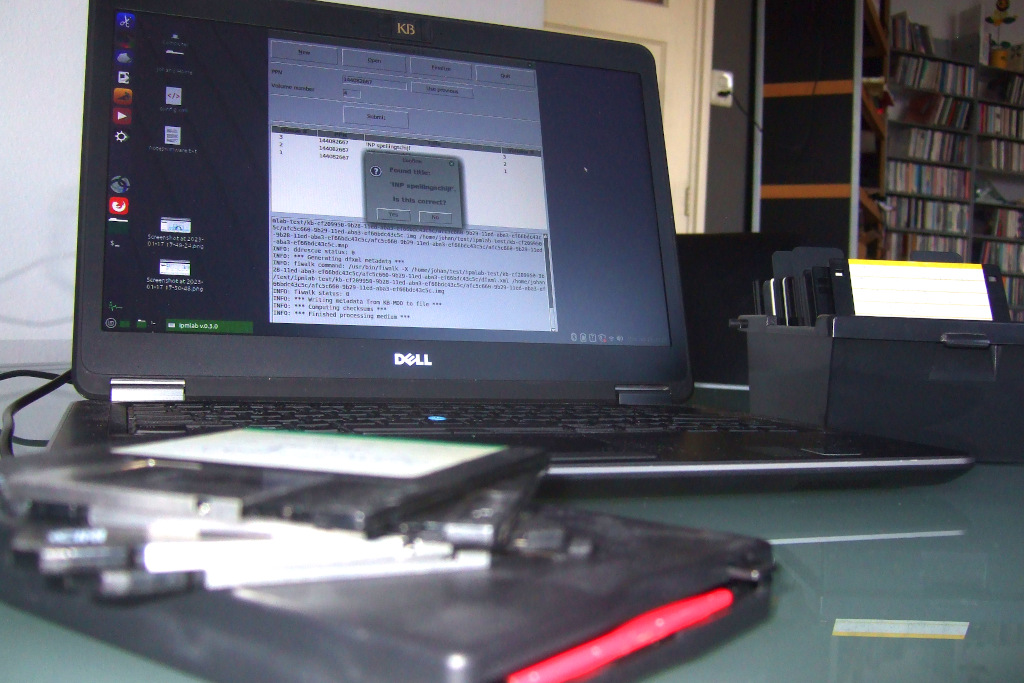
In 2017 I wrote a blog post on Iromlab (an acronym for “Image and Rip Optical Media Like A Boss”), a custom-built software tool that streamlines imaging and ripping of optical media using an Acronova Nimbie disc robot. The KB has been using Iromlab since 2019 as part of an ongoing effort to preserve the information contained in its vast collection of legacy optical media. This project is expected to reach its completion later this year, but as demonstrated by this earlier inventory, our deposit collection also contains various other types of legacy media that are under threat of becoming inaccessible. Out of these, 3.5 inch floppy disks are the most common data carriers (after optical media), so it made sense to focus on these as a next step.
Using the existing Iromlab-based workflow as a starting point, I created a preliminary workflow tool that can be used for imaging our 3.5” floppies (and various other types portable media). In this post I’ll explain how this tool came about, and highlight some of the challenges I encountered during its development.
As a total collapse of Twitter is becoming more likely every day, many Twitter users have started to archive their personal data from the platform while it still exists. Twitter allows you to request and download your personal archive. Even though this works well, and the quality of the archive is surpringly good, it does have some shortcomings. The result of these shortcomings will be that some information in the archive (e.g. on followed accounts and followers) will be lost once Twitter ceases to exist. Some other information (in particular full, unshortened URLs) is included in the archive, but it is not easily accessible from the main HTML interface. The good news is, that some excellent tools exist to fix these shortcomings.
In this post I outline the workflow I used to preserve my own Twitter archive, and while doing so I also provide some background information on the shortcomings of the Twitter archive. Since some of these steps may, at first sight, be a little daunting for less tech-savvy readers, I’ve tried to provide step-by-step instructions where possible.
Dutch electro outfit the Digital Dark Age Crew are one of the forgotten legends that used to be a mainstay of Rotterdam’s late 90s to mid-2000s underground electro scene. Their music was characterised by relentless electro beats, sparse synth lines, and lyrics that typically commented on the fragility and transience of digital media and digital information in general. In a twisted turn of events, this very theme would eventually define the Digital Dark Age Crew’s own history, ultimately leading to the group’s dramatic demise in 2007. After a fifteen year absence, the Digital Dark Age Crew have now made a long overdue comeback with their new track “Wheel Out the Digital Dark Age Klaxon”, which was released today on the occasion of World Digital Preservation Day 2022. Time to take a look back at the history of the Digital Dark Age Crew, and their continued relevance today!
This blog post covers some techniques that can be used to identify storage media and storage devices using Python and the Windows API. This can be useful for distinguishing between different types of portable storage media, such as floppy disks and USB thumb drives. It also presents a demo script that integrates these techniques.
It’s been a while since the last release of the Isolyzer tool, but after four years of near-inactivity I just published Isolyzer 1.4. In this post I provide some background information on how this release came about, and I briefly explain the main changes.